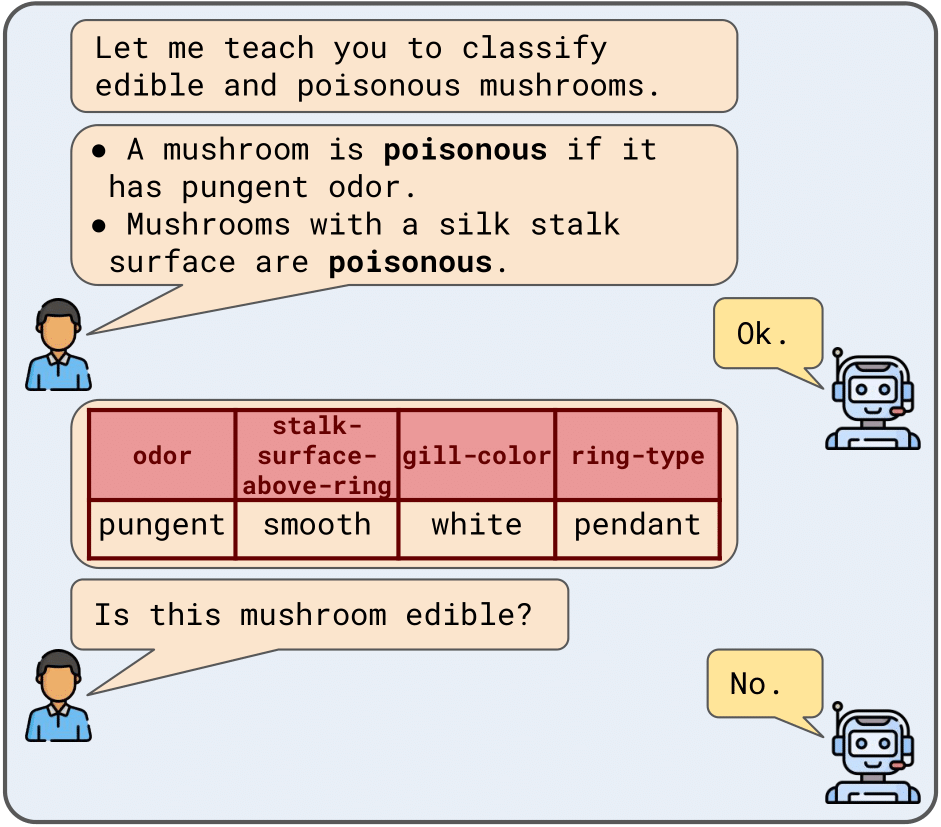
What is CLUES?
CLUES is a benchmark for Classifier Learning Using natural language ExplanationS, consisting of a
range of classification tasks over structured
data along with natural language supervision
in the form of explanations. CLUES consists
of 36 real-world (CLUES-Real) and 144 synthetic (CLUES-Synthetic) classification tasks.
It contains crowdsourced explanations describing real-world tasks from multiple teachers and programmatically generated explanations for the synthetic tasks.
The dataset has been created by a team of NLP researchers at UNC Chapel Hill.
For more details about CLUES, please refer to our paper:
Baselines
Our code for the baselines and the ExEnt model are hosted in the GitHub repository linked below
Citation
If you use CLUES in your research, please cite our paper with the following BibTeX entry
@inproceedings{menon2022clues,
Author = {Menon, Rakesh R. and Ghosh, Sayan and Srivastava, Shashank}
Title = {{CLUES}: {A} {B}enchmark for {L}earning {C}lassifiers using {N}atural {L}anguage {E}xplanations},
Year = 2022,
Journal = {In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (to appear)}
}